General
What is Go kit?
Go kit is a collection of Go (golang) packages (libraries) that help you build robust, reliable, maintainable microservices. It was originally conceived as a toolkit to help larger (so-called modern enterprise) organizations adopt Go as an implementation language. But it very quickly “grew downward”, and now serves smaller startups and organizations just as well. For more about the origins of Go kit, see Go kit: Go in the modern enterprise.
Why should I use Go kit?
You should use Go kit if you know you want to adopt the microservices pattern in your organization. Go kit will help you structure and build out your services, avoid common pitfalls, and write code that grows with grace.
Go kit can also help to justify Go as an implementation language to stakeholders like engineering managers or tech leads. Go kit de-risks both Go and microservices by providing mature patterns and idioms, written and maintained by a large group of experienced contributors, and validated in production environments.
Who is behind Go kit?
Go kit was originally conceived by Peter Bourgon, but is now built and maintained by a large group of contributors from a diverse set of backgrounds and organizations. Go kit is presently an all-volunteer effort, and has no commercial backing.
Is Go kit production-ready?
Yes. Go kit is being used in production in several organizations, large and small.
Which organizations are using Go kit?
Watch this space :)
How does Go kit compare to Micro?
Like Go kit, Micro describes itself as a microservice toolkit. But unlike Go kit, Micro also describes itself as a microservice ecosystem. It takes a broader view, encoding expectations and opinions about the infrastructure and architecture. In short, I think Micro wants to be a platform; Go kit, in contrast, wants to integrate into your platform.
Architecture and design
Introduction — Understanding Go kit key concepts
If you’re coming from Symfony (PHP), Rails (Ruby), Django (Python), or one of the many popular MVC-style frameworks out there, the first thing you should know is that Go kit is not an MVC framework. Instead, Go kit services are laid out in three layers:
- Transport layer
- Endpoint layer
- Service layer
Requests enter the service at layer 1, flow down to layer 3, and responses take the reverse course.
This may be a bit of an adjustment, but once you grok the concepts, you should see that the Go kit design is well-suited for modern software design: both microservices and so-called elegant monoliths.
Transports — What are Go kit transports?
The transport domain is bound to concrete transports like HTTP or gRPC. In a world where microservices may support one or more transports, this is very powerful; you can support a legacy HTTP API and a newer RPC service, all in a single microservice.
When implementing a REST-ish HTTP API, your routing is defined within a HTTP transport. It’s most common to see routes defined in a HTTP Router function like this:
r.Methods("POST").Path("/profiles/").Handler(httptransport.NewServer(
e.PostProfileEndpoint,
decodePostProfileRequest,
encodeResponse,
options...,
))
Endpoints — What are Go kit endpoints?
An endpoint is like an action/handler on a controller; it’s where safety and antifragile logic lives. If you implement two transports (HTTP and gRPC), you might have two methods of sending requests to the same endpoint.
Services — What is a Go kit service?
Services are where all of the business logic is implemented. A service usually glues together multiple endpoints. In Go kit, services are typically modeled as interfaces, and implementations of those interfaces contain the business logic. Go kit services should strive to abide the Clean Architecture or the Hexagonal Architecture. That is, the business logic should have no knowledge of endpoint- or especially transport-domain concepts: your service shouldn’t know anything about HTTP headers, or gRPC error codes.
Middlewares — What are middlewares, in Go kit?
Go kit tries to enforce a strict separation of concerns through use of the middleware (or decorator) pattern. Middlewares can wrap endpoints or services to add functionality, such as logging, rate limiting, load balancing, or distributed tracing. It’s common to chain multiple middlewares around an endpoint or service.
Design — How is a Go kit microservice modeled?
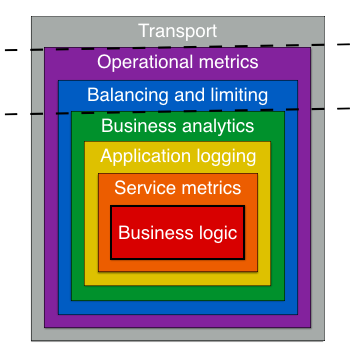
Putting all these concepts together, we see that Go kit microservices are modeled like an onion, with many layers. The layers can be grouped into our three domains. The innermost service domain is where everything is based on your specific service definition, and where all of the business logic is implemented. The middle endpoint domain is where each method of your service is abstracted to the generic endpoint.Endpoint, and where safety and antifragile logic is implemented. Finally, the outermost transport domain is where endpoints are bound to concrete transports like HTTP or gRPC.
You implement the core business logic by defining an interface for your service and providing a concrete implementation. Then, you write service middlewares to provide additional functionality, like logging, analytics, instrumentation — anything that needs knowledge of your business domain.
Go kit provides endpoint and transport domain middlewares, for functionality like rate limiting, circuit breaking, load balancing, and distributed tracing — all of which are generally agnostic to your business domain.
In short, Go kit tries to enforce strict separation of concerns through studious use of the middleware (or decorator) pattern.
Dependency Injection — Why is func main always so big?
Go kit encourages you to design your services as multiple interacting components, including several single-purpose middlewares. Experience has taught us that the most comprehensible, maintainable, and expressive method of defining and wiring up the component graph in a microservice is through an explicit and declarative composition in a large func main.
Inversion of control is a common feature of other frameworks, implemented via Dependency Injection or Service Locator patterns. But in Go kit, you should wire up your entire component graph in your func main. This style reinforces two important virtues. By strictly keeping component lifecycles in main, you avoid leaning on global state as a shortcut, which is critical for testability. And if components are scoped to main, the only way to provide them as dependencies to other components is to pass them explicitly as parameters to constructors. This keeps dependencies explicit, which stops a lot of technical debt before it starts.
As an example, let’s say we have the following components:
- Logger
- TodoService, implementing the Service interface
- LoggingMiddleware, implementing the Service interface, requiring Logger and concrete TodoService
- Endpoints, requiring a Service interface
- HTTP (transport), requiring Endpoints
Your func main should be wired up as follows:
logger := log.NewLogger(...)
var service todo.Service // interface
service = todo.NewService() // concrete struct
service = todo.NewLoggingMiddleware(logger)(service)
endpoints := todo.NewEndpoints(service)
transport := todo.NewHTTPTransport(endpoints)
At the cost of having a potentially large func main, composition is explicit and declarative. For more general Go design tips, see Go best practices, six years in.
Deployment — How should I deploy Go kit services?
It’s totally up to you. You can build a static binary, scp it to your server, and use a supervisor like runit. Or you can use a tool like Packer to create an AMI, and deploy it into an EC2 autoscaling group. Or you can package your service up into a container, ship it to a registry, and deploy it onto a cloud-native platform like Kubernetes.
Go kit is mostly concerned with good software engineering within your service; it tries to integrate well with any kind of platform or infrastructure.
Errors — How should I encode errors?
Your service methods will probably return errors. You have two options for encoding them in your endpoints. You can include an error field in your response struct, and return your business domain errors there. Or, you can choose to return your business domain errors in the endpoint error return value.
Both methods can be made to work. But errors returned directly by endpoints are recognized by middlewares that check for failures, like circuit breakers. It’s unlikely that a business-domain error from your service should cause a circuit breaker to trip in a client. So, it’s likely that you want to encode errors in your response struct.
addsvc contains examples of both methods.
More specific topics
Transports — Which transports are supported?
Go kit ships with support for HTTP, gRPC, Thrift, and net/rpc. It’s straightforward to add support for new transports; just file an issue if you need something that isn’t already offered.
Service Discovery — Which service discovery systems are supported?
Go kit ships with support for Consul, etcd, ZooKeeper, and DNS SRV records.
Service Discovery — Do I even need to use package sd?
It depends on your infrastructure.
Some platforms, like Kubernetes, take care of registering services instances and making them discoverable automatically, via platform-specific concepts. So, if you run on Kubernetes, you probably don’t need to use package sd.
But if you’re putting together your own infrastructure or platform with open-source components, then your services will likely need to register themselves with the service registry. Or if you have reached a scale where internal load balancers become a bottleneck, you may need to have your services subscribe to the system of record directly, and maintain their own connection pools. (This is the client-side discovery pattern.) In these situations, package sd will be useful.
Observability — Which monitoring systems are supported?
Go kit ships with support for modern monitoring systems like Prometheus and InfluxDB, as well as more traditional systems like statsd, Graphite, and expvar, and hosted systems like Datadog via DogStatsD and Circonus.
Observability — Which monitoring system should I use?
Logging — Why is package log so different?
Experience has taught us that a good logging package should be based on a minimal interface and should enforce so-called structured logging. Based on these invariants, Go kit’s package log has evolved through many design iterations, extensive benchmarking, and plenty of real-world use to arrive at its current state.
With a well-defined core contract, ancillary concerns like levels, colorized output, and synchronization can be easily bolted on using the familiar decorator pattern. It may feel a little unfamiliar at first, but we believe package log strikes the ideal balance between usability, maintainability, and performance.
For more details on the evolution of package log, see issues and PRs 63, 76, 131, 157, and 252. For more on logging philosophy, see The Hunt for a Logger Interface, Let’s talk about logging, and Logging v. instrumentation.
Logging — How should I aggregate my logs?
Collecting, shipping, and aggregating logs is the responsibility of the platform, not individual services. So, just make sure you’re writing logs to stdout/stderr, and let another component handle the rest.
Panics — How should my service handle panics?
Panics indicate programmer error and signal corrupted program state. They shouldn’t be treated as errors, or ersatz exceptions. In general, you shouldn’t explicitly recover from panics: you should allow them to crash your program or handler goroutine, and allow your service to return a broken response to the calling client. Your observability stack should alert you to these problems as they occur, and you should fix them as soon as possible.
With that said, if you have the need to handle exceptions, the best strategy is probably to wrap the concrete transport with a transport-specific middleware that performs a recover. For example, with HTTP:
var h http.Handler
h = httptransport.NewServer(...)
h = newRecoveringMiddleware(h, ...)
// use h normally
Persistence — How should I work with databases and data stores?
Accessing databases is typically part of the core business logic. Therefore, it probably makes sense to include an e.g. *sql.DB pointer in the concrete implementation of your service.
type MyService struct {
db *sql.DB
value string
logger log.Logger
}
func NewService(db *sql.DB, value string, logger log.Logger) *MyService {
return &MyService{
db: db,
value: value,
logger: logger,
}
}
Even better: consider defining an interface to model your persistence operations. The interface will deal in business domain objects, and have an implementation that wraps the database handle. For example, consider a simple persistence layer for user profiles.
type Store interface {
Insert(Profile) error
Select(id string) (Profile, error)
Delete(id string) error
}
type databaseStore struct{ db *sql.DB }
func (s *databaseStore) Insert(p Profile) error { /* ... */ }
func (s *databaseStore) Select(id string) (Profile, error) { /* ... */ }
func (s *databaseStore) Delete(id string) error { /* ... */ }
In this case, you’d include a Store, rather than a *sql.DB, in your concrete implementation.